EPFL的研究人员已经开发出一种算法,可以像训练数字神经网络一样精确地训练模拟神经网络,从而能够开发出更高效的替代耗能的深度学习硬件。
凭借其通过算法“学习”而不是传统编程处理大量数据的能力,像Chat-GPT这样的深度神经网络的潜力似乎是无限的。但是,随着这些系统的范围和影响不断扩大,它们的规模、复杂性和能源消耗也在增加——后者的重要性足以引起人们对全球碳排放的担忧。
虽然我们经常认为技术进步是从模拟到数字的转变,但研究人员现在正在寻找数字深度神经网络的物理替代品来解决这个问题。EPFL工程学院波浪工程实验室的罗曼·弗勒里就是这样一位研究人员。在《科学》杂志上发表的一篇论文中,他和他的同事描述了一种训练物理系统的算法,与其他方法相比,该算法显示出更快的速度、更强的鲁棒性和更低的功耗。
“我们成功地在三个基于波的物理系统上测试了我们的训练算法,这些系统使用声波、光波和微波来携带信息,而不是电子。但是我们的通用方法可以用来训练任何物理系统,”第一作者和LWE研究员Ali Momeni说。
一种“生物学上更合理”的方法
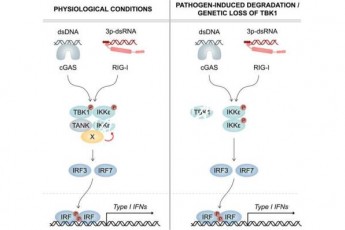
神经网络训练指的是帮助系统学习为图像或语音识别等任务生成参数的最优值。它通常包括两个步骤:前向传递,其中数据通过网络发送,并根据输出计算误差函数;以及反向传递(也称为反向传播或BP),其中计算误差函数相对于所有网络参数的梯度。
在重复的迭代中,系统根据这两个计算更新自身,以返回越来越精确的值。这个问题?除了能源密集之外,BP也不太适合物理系统。事实上,训练物理系统通常需要BP步骤的数字孪生,这是低效的,并且存在现实与模拟不匹配的风险。
科学家们的想法是用第二次通过物理系统的前向传递来取代BP步骤,从而在本地更新每个网络层。除了降低功耗和消除对数字孪生的需求之外,这种方法更好地反映了人类的学习。
“神经网络的结构受到大脑的启发,但大脑不太可能通过BP来学习,”Momeni解释说。“这里的想法是,如果我们在本地训练每个物理层,我们就可以使用我们实际的物理系统,而不是首先建立一个数字模型。因此,我们开发了一种生物学上更合理的方法。”
EPFL的研究人员与法国国家科学研究院研究院的菲利普·德尔·霍恩和微软研究院的巴巴克·拉赫马尼一起,使用他们的物理局部学习算法(PhyLL)来训练实验声学和微波系统以及一个模拟光学系统,以分类元音和图像等数据。与基于bp的训练相比,该方法不仅具有相当的准确性,而且具有鲁棒性和适应性,即使在暴露于不可预测的外部扰动的系统中也是如此。
模拟的未来?
虽然LWE的方法是第一个深度物理神经网络的无bp训练,但仍然需要对参数进行一些数字更新。“这是一种混合训练方法,但我们的目标是尽可能减少数字计算,”莫莫尼说。
研究人员现在希望在一个小规模的光学系统上实现他们的算法,最终目标是提高网络的可扩展性。
“在我们的实验中,我们使用了多达10层的神经网络,但它仍然可以处理100层、数十亿个参数的神经网络吗?这是下一步,需要克服物理系统的技术限制。”